本主要介绍sift特征,opensift算法和图像拼接
#stitch资料整理
- sift详细介绍可以参考SIFT算法详解及应用(讲的很详细).pdf(我忘记从什么地方下的了,作者请原谅)。
- 源代码可在这里下载。
说明
在这个代码内有详细的程序注释,他是基于opensift库(库的介绍在这里,中文翻译在这里),在VS2012上使用C++编写的。 - 在这篇文章中Distinctive Image Features from Scale-Invariant Keypoints作者详细描写了sift构造过程,下边是对文中不知道知识点的补充,同时可以参考该网页SIFT算法:DOG尺度空间生产,作者对上述论文做了一些翻译。
说明
a. 关于梯度,Jacobi 矩阵,拉普拉斯矩阵可参考这里
b. 对于使用DoG来近似σ2∇2G,有如下优点:
σ2∇2G需要使用两个方向的高斯二阶微分卷积核,而DoG直接使用高斯卷积核,省去了对卷积核的生成的运算量;DoG保留了各个高斯尺度空间的图像,这样,在生成某一空间尺度的特征时,可以直接尺度空间图像,而无需重新再次生成该尺度的图像。 c. 在文章Distinctive Image Features from Scale-Invariant Keypoints3.1节中第二段描写圆,椭圆的例子没有看懂????????;3.2节(不明白关键点的重复性指什么?是多次实验都能检测出吗?)主要讲述了为什么每组中选择3层,但是没有看懂(初步看的好像是说,由于大多数极值点不稳定,在仿射图像下很多极值点都被舍掉了,导致随着每组层数的增多,重复性不但没有升反而降了;随着每组层数的增多,识别到的极值点也增多,但是计算量也变大,权衡之际选择3层);3.3节讲述了为什么滤波因子为什么选择1.6(随着滤波尺度的增大,关键点的重复性增加,但是考虑成本选择比较好的1.6)和第一张图片要二次插值,但是不怎么明白 看不下去了,看不下去了。Ai!!! - 透视变换(perspective或者是homograph)
透视变换(Perspective Transformation)是将图片投影到一个新的视平面(Viewing Plane),也称作投影映射(Projective Mapping)。通用的变换公式为:
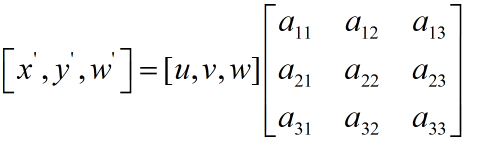
u,v是原始图片左边,对应得到变换后的图片坐标x,y,其中\(x=x^'/w^',y=y^'/w^'\) -
图像拼接
这里有两种拼接方法:
① 简易拼接方法的过程是:首先将右图img2经变换矩阵H变换到一个新图像中,然后直接将左图img1加到新图像中,这样拼接出来会有明显的拼接缝,但也是一个初步的成品了。
② 另一种方法首先也是将右图img2经变换矩阵H变换到一个新图像中,然后图像的融合过程将目标图像分为三部分,最左边完全取自img1中的数据,中间的重合部分是两幅图像的加权平均,重合区域右边的部分完全取自img2经变换后的图像。加权平均的权重选择也有好多方法,比如可以使用最基本的取两张图像的平均值,但这样会有明显的拼接缝。这里首先计算出拼接区域的宽度,设d1,d2分别是重叠区域中的点到重叠区域左边界和右边界的距离,则使用如下公式计算重叠区域的像素值: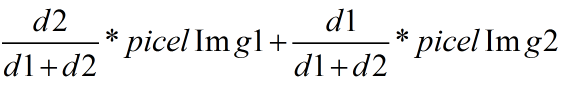
这样就可以实现平滑过渡。
#stitch程序伪代码 - sift算法实现伪代码:
a. 读取两张图片img1,img2,且归一到同等大小尺度;
b. 分别提取两张图像img1,img2的sift特征点feature1,feature2:
1.初始化img1:返回灰度图
1) 把图像转换成32为浮点灰度图,灰度值范围为(0-1);
2) if(第一张图像2倍插值)
计算高斯核尺度;$$\sqrt {\sigma*\sigma-4*intsigma*intsigma}$$
原始图像使用双三次插值扩大图像;双三次插值详解[可见](/cv/inter/)
使用高斯平滑该图像
else
计算高斯核尺度;$$\sqrt {\sigma*\sigma-intsigma*intsigma}$$
使用高斯平滑该图像
2.计算高斯塔层数(组数);
3.创建高斯金字塔,返回建好的金字塔:
1)初始化高斯滤波因子,每组内各层的滤波因子为$$k^n*sigma,n$$为组内的第几层,初始化高斯金字塔,一共有intvls组,组内有s+3层;
2)遍历组o(0——octivs-1);
遍历层i(0——intvls+3-1);
if是第0组0层直接把图像添加到金字塔内,若是其它组内第0层,把上一组内倒数第3层加入金字塔内;
else对当前组内上一层进行滤波加入金字塔内;
4.创建高斯差分金字塔,返回差分金字塔:
1)初始化差分金字塔,一共有intvls组,组内有s+2层;
2)遍历组o(0——octivs-1);
遍历层i(0——intvls+2-1);
同组内相邻金字塔相减加入差分金字塔;
5.极值点检测,返回的是特征点,里边包含该点的位置(组层行列和具体在第一张图像的位置):
对高斯差分金字塔遍历组o(0——octivs-1);
遍历层i(1——intvls-1);
遍历差分图像的高(r=SIFT_IMG_BORDER——dog_pyr[o][0]->height-SIFT_IMG_BORDER)
遍历差分图像的宽(c=SIFT_IMG_BORDER——dog_pyr[o][0]->width-SIFT_IMG_BORDER)
a.判断该点大于每个阈值(该阈值与组内的层数成反比)
b.判断该点是否为邻近点(包括同层内的8邻域和相邻层内的8邻域)的最值(最大或最小)##为什么这样才认为是极值点##;
c.对满足上边两个条件的点插值:
a)while(是否满足插值次数):
1)进行一次插值,返回:
i)计算该点的导数dD(包含x,y和层导数);
ii)计算该点的海森矩阵H(包含xx,yy,ss,xy,xs,ys);
iii)根据deltaX = - H^(-1) * dD(可理解为牛顿迭代法的增量);
2)判断deltaX全<0.5,直接跳出就是,因为该点就是关键点(注意关键点的坐标是整数)。
3)修正该点坐标;
b)计算关键点(此关键点不一定是遍历时的值了,因为在上个while循环中已经改变了)的值D + 0.5 * dD^T * X;
c)判断该点值是否过小;
d)计算该点位置(x,y)其中x=(c+xc)*pow(2.0,octv),因为该图像尺度已经改变了,应该变换到原始图像位置上;保存该点所在的组,层,行,列,和偏移量
d判断当前检测出的关键点是否在边界上:
a)计算该点的海森矩阵H(只包含dxx,dxy,dyy)
b)判断该点海森矩阵的tr(H)^2 / det(H)是否大于某个(r+1)(r+1)/r,若是则证明该点为关键点
e把满足的特征假如特征系列内
6.计算极值点的尺度:
遍历特征点:
计算特征点所用的高斯滤波函数的尺度sigma*pow(2.0,ddata->octv+intvl/intvls),该尺度是相对于原始图像而言;
7.判断是否图像开始时进行了插值,应该改变特征点的位置坐标(因为在前面几步中我们计算出来的位置是相对与第一张图像的,同时尺度也要除以2,因为2倍插值相当于对原始图像1/2滤波类似于把第0组金字塔退掉)
8.为每个特征添加方向:
遍历每个特征点:
a.取出第i个特征,特征数据;
b.在该特征点计算方向直方图,搜索半径3*1.5*σ,:
遍历该点区域内行:
遍历该点区域内列:
计算点的梯度模与方向;
计算该方向应分到直方图哪个柱上;
计算该点的权重(不知道为什么哈);
把该点权重*模值累加计入直方图内作为直方图柱的高度;
c.邻域平滑直方图多次,弥补不稳定因素;
d.找主方向(即最高的直方柱);
e.找辅助方向:
a)遍历直方图:
若此时直方柱高于两侧的直方柱且高于主方向*80%:
计算该直方图精确位置(二次曲线拟合,求二次曲线极值坐标)
计算该点方向,并把该特征克隆添加到特征序列中
9.计算每个特征点的描述符,返回特征向量(里边包含了描述符和前几步算的位置信息):
遍历特征点:
a.计算该点的直方图,该直方图大小为d*d*n:(与上一步直方图不一样哈)
确定搜索半径;
遍历该点区域内行:
遍历该点区域内列:
a.计算该点位于哪个直方图:
b.删除不该计算的点(因为搜索半径很大,有些点不必要计算,当然程序中放宽了限制,认为(-1-d的都可以)但是在e步又做了限制)计算该点梯度幅度和方向;
c.方向应该减去主方向;计算该方向应该位于直方图哪个柱子上;
d.计算权重##不知道为什么那么计算计算发##:
e.把该点加进直方图中,注意其中有使用了一次计算权重。
b.把该直方图作为特征描述符:
归一化描述符(不是除以所有值的和,而是所有值平方的开方,其实这两种都可以);
门限化描述符,认为太小的值归一到限定阈值处;
再归一化;
把描述符规划到(0-255);
10.按尺度排序特征序列;
c.第一幅图特征点KNN树的建立,返回整个树:
1.建立根(该节点下的特征,以该节点为根下边一共有多少个节点(特征),该节点枢轴索引设为-1)
2.扩展子树:
a.判断是否下边没有特征了(是否到达叶子)是则退出;
b.确定节点的枢纽索引和枢纽值:
a)遍历每个特征的维数(128):
计算该纬度下该节点下所有特征点描述符的均值;
计算方差;
找到哪个纬度下方差最大;
b)选取最大方差纬度下的所有特征,进行排序,求取中间值;
c)保存纬度为枢纽索引,中间值为枢纽值;
c.划分特征:
a)遍历剩下的所有特征;
若当前特征枢纽索引上的值小于枢纽值;则把该特征移到左侧,大于的移动当前位置;这样最后小的在枢纽值的特征在最左边,大的依次依据位置往后移。最后不要忘记把枢纽索引的特征放在小于枢纽值的后边;
b)判断是否所有的特征同一侧,则此节点就是叶子节点;
c)把小的特征点挂在左树上,大的挂在右树上,把此时节点当作根节点初始化。
c.从a-c迭代扩展子树
d.遍历第二张图的特征点:
根据bbf在上边所建的寻找与该特征点最相近的两个第一幅图的特征:
1.创建默认大小的优先级堆栈;
2.把KNN树根压入优先级堆栈,
3.进入while循环,查找最近点:
a.从堆栈里取出优先级最高的特征;
b.从上一步取出的特征点为根搜索与特征最近的特征,直到叶子:
进入while知道叶子节点:
a)取出当前树节点特征的枢纽索引和枢纽值;
b)目标特征点ki维的数据小于等于kv:则下一步往左树搜索,右树最为候选节点;同理,大于;
c)将候选节点unexpl根据目标特征点ki维与其父节点的距离插入到优先队列中,距离越小,优先级越大,越靠近栈顶需要学习一下CvSeq;cvSeqSort
Click the link below to go back to index:
Go back