本文主要是在准备华为精英大赛时学习的一点基本图的知识点,主要是包括图的搜索,图的搜索算法可以用来发现图的结构。
图的表示
对于图\(G=(V,E)\),主要有两种表示方法:邻接链表和邻接矩阵,或许还可以加一个十字链接表。
邻接链表
-
主要用于稀疏图(边的条数$$ E 远远小于$$ V ^2$$的图);最常用; - 对于每个节点\(u \epsilon V\),邻接链表\(Adj[u]\)包含所有与结点\(u\)之间有边相连的结点。
缺点
无法快速判断一条\((u,v)\)是否是图中的一条边,唯一的办法是在邻接链\(Adj[u]\)里边搜索结点\(v\);
邻接矩阵
主要用于稠密图(边的条数\(|E|接近\)|V|^2$$的图);或者如果需要快速判断任意两个结点之间是否有边相连;或者是当图的规模比较小时;或者对于无向图来说,每个矩阵元素可以用1位空间;
缺点
消耗更大的存储空间;
图的属性
对图进行操作的多数算法需要维持图中结点或边的属性,如\(v.d\)表示结点\(v\)的属性\(d\);\((u,v).f\)表示边\((u,v)\)的属性;是否我们可以找出图的某种属性呢,对于华为这个比赛而言的对于图属性的存储没有最好的方法,因环境而已;
广度优先搜索
广度优先搜索是最简单的图搜索算法之一,也是许多重要的图算法的原型。既可以发现从源节点s到达所有结点,同时计算出到达所有结点的距离(最小的边数),并创建一棵广度优先搜索树(边数为结点数减一)。
其思想是:该算法是将已发现结点和未发现结点之间的边界,沿其广度方向向外扩展。也就是说,算法需要在发现所有距离源节点s为k的所有结点之后,才会发现距离源节点s为k+1的其他结点。
算法实现过程:在没有寻到某个结点时为白色;寻到后但还在堆栈里为白色;从堆栈剔除后变为黑色。该算法的while循环中的不变为:队列Q里面包含的是灰色结点集合。
复杂度为\(\Theta(E+V)\),以前的时候从来没有注意过这个复杂度,但当考虑到运行效率时这个尤为重要。
可得到最短路径。深度优先搜索
- 所使用的策略如其名字所隐含的一样:只要可能,就在图中尽量“深入”;
- 树上说广度优先搜索的前驱子图形成一棵树,而深度优先搜索的前驱子图可能由多棵树组成,不明白????;
- 复杂度为\(\Theta(E+V)\);
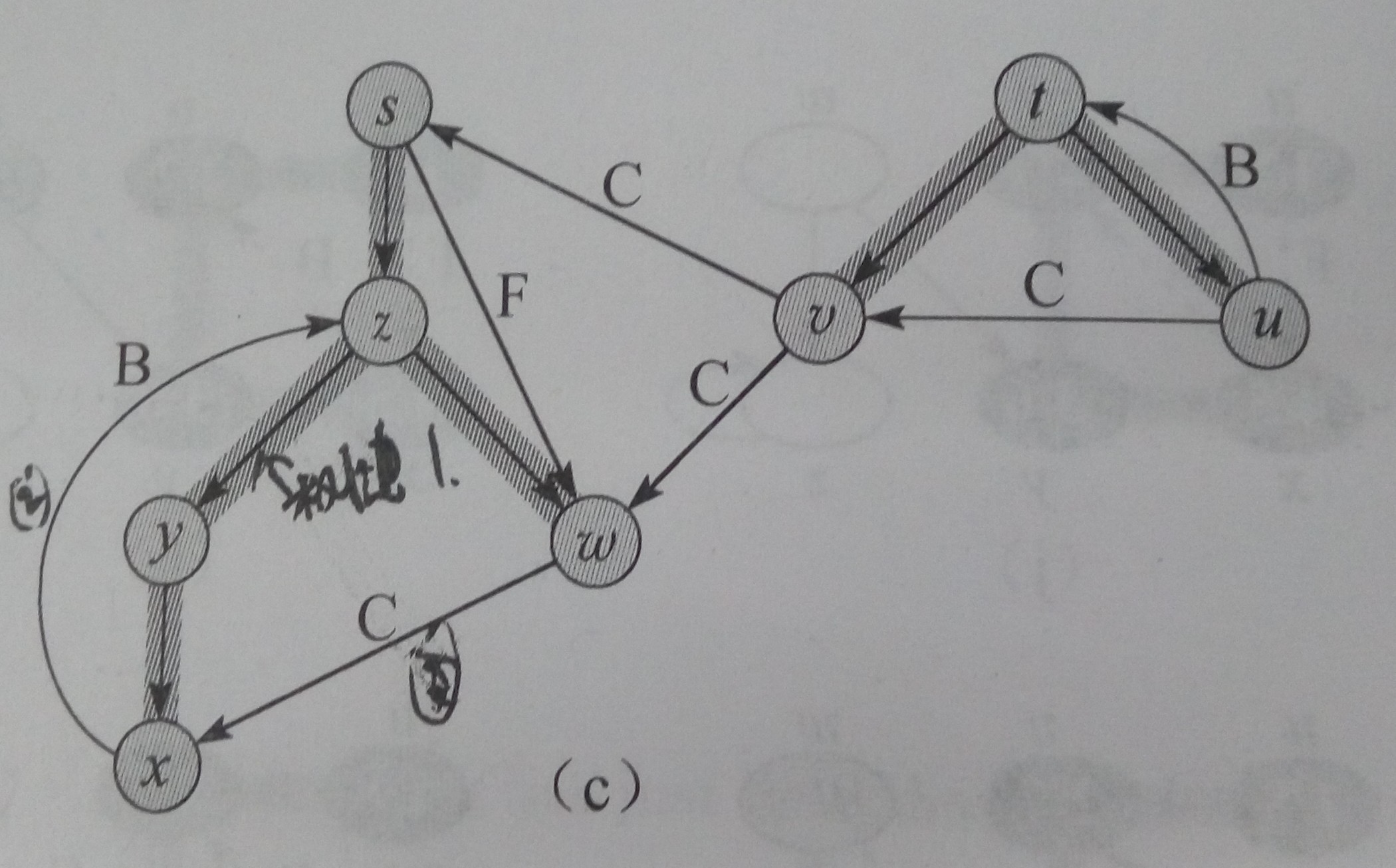
- 可以提供边的分类:树边,后向边(B),前向边(F),横向边(C),编号的含义看下图
!深度优先搜索树
在无向图中不存在前向边和横向边。拓扑排序
- 对于一个有向无环图\(G=(V,E)\)来说,其拓扑排序时G中所有结点的一种线性次序,可以看作是将图的所有结点在一条水平线上排开,图的所有有向边都从左指向右。
- 可使用深度优先方法。结点完成搜索越小,就越排在右边。(在深度优先搜索中不会产生后向边)
- 复杂度为\(\Theta(E+V)\);
强连通图
-
单源最短路径
Dijkstra算法
{kind=link}
Click the link below to go back to index:
Go back